Michael Tamblyn on 6 projects that could change publishing for the better

I found a lot of good thought-provoking material in this publishing-oriented slide set. Be sure to read the notes down below each slide. My favorite one is "if you show this (xml process) to most editors, they're going to start drinking at their desks."
"XML - Why Bother" presentation
Mary Harper found this great little presentation by Hachette Book Group on Slideshare.net. The illustrations of traditional content process vs. an XML process are really nice and understandable. Indexing as metadata fits into this flow, but of course is not included in the illustration. We need to keep after publishers to understand that the indexing is part of the necessary metadata that flows with the content.
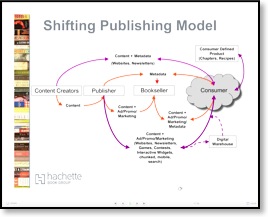
XML in publishing
For Young, the reason to use XML is simple--it allows
Hachette to develop and deliver content to readers in
the formats they want. It also saves money on
production costs and can lead to new revenue streams.
Young noted there are some estimates that put the
number of handheld devices in the world at 3 billion,
which, he said, equates to “3 billion blank pages.”
To reach that audience, content needs to be flexible
enough to be delivered in a variety of ways, Young
said. Since XML uses a content-centric,
design-agnostic approach to production, an XML file
is uniquely suited to deliver content as an e-book or
through print-on-demand, he said.
The effective use of XML, however, requires
cooperation and commitment throughout the production
process, beginning with editors and authors, Young
said. By using XML to tag content, editors are in a
position to help shape how that content will be
delivered, Young said, predicting that “tagging will
become as ingrained as the blue pencil.” Young
acknowledged that editors will need to be trained on
how to tag and that they will need to develop new
skills and have new tools. “It will be a sea change”
about who does what, Young said, but ultimately the
changes will open up new revenue opportunities.
Speakers on the rest of the morning’s panels expanded
on various themes introduced by Young. Brian O’ Leary
of Magellan Media Consulting Partners, said that
publishers will only be able to fully capitalize n
XML if they adopt a discipline approach to using it,
which begins with editors tagging the information. He
noted that some types of books will work benefit more
from XML than others (a point made by one of the
conference organizers, Mike Shatzkin in his What the
Hell is XML piece which appeared in the Dec. 15 PW).
Rebecca Goldthwaite of Cengage Learning noted that
among the lessons learned in implementing XML there
was the need for a “culture change,” and for XML to
be used consistently throughout. Simon &
Schuster’s Steve Kotrch emphasized the ability using
XML gives a publisher to create more robust rights
databases that can be hooked to other databases to
exchange information.
Evan Schnittman of Oxford University Press touched on
the benefits of using XML in terms of improving
search results on Google. The ability to put books
(and other content) into “chunks” enhances the
chances that those books will be discovered through
traditional Google searches rather than only through
Google Book Search, Schnittman said. He noted that
OUP has created a “significant revenue stream” as a
result of its books being discovered through Google.
OUP has 15,564 titles in Google Book Search, which
have generated more than 143 million page views,
Schnittman said which in turn has led to more than
734,000 clicks on a buy link or 47.2 buy clicks per
book. Bill O’Brien of the Copyright Clearance Center
also brought up chunking, noting that chunking leads
to “micro commerce,” which can accumulate late into a
significant sum. (CCC has dispersed $1 billion to
publishers since it was launched 30 years ago, he
said).
Multipurposing material is where they are looking to make their money next.