search
People are just like bears - information foraging
07/06/10 11:13
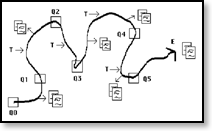
Marcia Bates' berrypicking model
In her landmark 1989 paper, www.gseis.ucla.edu/faculty/bates/berrypicking.html?referer=http%3A%..., Marcia Bates outlined search as an evolutionary process. Users often begin with a general query, glean a few nuggets from the initial results, reformulate their query based on that new knowledge, and then repeat this process. Like a bear foraging for food in the forest, knowledge seekers tend to rapidly migrate from one patch of information to the next.
While this iterative behavior is true of virtually everyone using search, there are two key factors that distinguish some users from others: domain expertise and search expertise(though www.boxesandarrows.com/view/search-behavior?referer=http%3A%2F%2Ftw..., John Ferrara has identified several additional factors). Some websites, for example, may be able to assume that users are highly literate in a specific topic, while other websites may need to design for a range of expertise in a variety of subjects (the case for web search engines). In addition, users experienced at using search interfaces will be more capable of utilizing sophisticated search tools, but less experienced users will demand less complexity.
Keep reading here
I can't stand the blithe write-off
05/30/10 10:48
Jeremy Horwitz doesn't
get it at all:
The iBooks-formatted book Ratio by Michael Ruhlman, for instance, can be stretched to a 3518-page tome or reduced to 223, just shy of the actual book’s 244—mostly because it’s missing the original’s index. And thanks to a magnifying glass icon at the top right of every page, the index is arguably unnecessary: you can search for any word in the book and get a complete, clickable list of its occurrences, plus links to Google and Wikipedia, and an integrated dictionary that can define virtually any word you touch.
One word searches work SO WELL on Google, why not on an ebook?
The iBooks-formatted book Ratio by Michael Ruhlman, for instance, can be stretched to a 3518-page tome or reduced to 223, just shy of the actual book’s 244—mostly because it’s missing the original’s index. And thanks to a magnifying glass icon at the top right of every page, the index is arguably unnecessary: you can search for any word in the book and get a complete, clickable list of its occurrences, plus links to Google and Wikipedia, and an integrated dictionary that can define virtually any word you touch.
One word searches work SO WELL on Google, why not on an ebook?
Archiving Twitter
04/16/10 10:22
Not everyone would think that the actor Ashton
Kutcher’s Twitter musings on his daily doings
constitute part of “the universal body of human
knowledge.”
But the Library of Congress, the 210-year-old guardian of knowledge and cultural history, thinks so.
The library will archive the collected works of Twitter, the blogging service, whose users currently send a daily flood of 55 million messages, all that contain 140 or fewer characters.
Library officials explained the agreement as another step in the library’s embrace of digital media.
Twitter, the Silicon Valley start-up, declared it “very exciting that tweets are becoming part of history.”
Read more at the NYT.
But the Library of Congress, the 210-year-old guardian of knowledge and cultural history, thinks so.
The library will archive the collected works of Twitter, the blogging service, whose users currently send a daily flood of 55 million messages, all that contain 140 or fewer characters.
Library officials explained the agreement as another step in the library’s embrace of digital media.
Twitter, the Silicon Valley start-up, declared it “very exciting that tweets are becoming part of history.”
Read more at the NYT.
Leah Guren on demographic differences in using Help content
03/27/10 08:04
Another
great session from WritersUA. Leah Guren has been
conducting usability tests on populations using
software help systems to perform simple tasks. In
this study, she found that language, experience, and
age affect task performance.
Some of her conclusions:
Gender made no difference - women look for Help content, or ignore Help content, as much as men.
Experience can make a big difference. It takes 8 good successful sessions with help to make up for one bad experience where it didn't help. -- think indexes?
Age is a huge factor, and native tongue as well. These are both modified by experience, i.e., an older user who was very experienced with using other help systems were just fine, but older newbie users were not. Those working in a second language who again had more experience were just fine, but it was a barrier if the user was a newbie.
58% of users distrust Help - due to bad experiences.
Small onscreen text that appears in a bar above or below the window is not seen at all.
Side panels also disappear.
When readers look at a table of contents online that contains a ton of hierarchical structures, they don't use it. When asked why, they said that none of the headings seemed to help. Leah said that to a user, their question is first level important. We can assume that they want it up at the main heading level in a toc, or it is useless to them. So again, think indexes, we are the great levelers for people who think their search is important enough to be available on a first level basis.
I wish she had tested indexes, but oh well.
Links inside a paragraph lose users completely.
Vocabulary was a huge issue - again, there we can help teach users the domain language.
Some of her conclusions:
Gender made no difference - women look for Help content, or ignore Help content, as much as men.
Experience can make a big difference. It takes 8 good successful sessions with help to make up for one bad experience where it didn't help. -- think indexes?
Age is a huge factor, and native tongue as well. These are both modified by experience, i.e., an older user who was very experienced with using other help systems were just fine, but older newbie users were not. Those working in a second language who again had more experience were just fine, but it was a barrier if the user was a newbie.
58% of users distrust Help - due to bad experiences.
Small onscreen text that appears in a bar above or below the window is not seen at all.
Side panels also disappear.
When readers look at a table of contents online that contains a ton of hierarchical structures, they don't use it. When asked why, they said that none of the headings seemed to help. Leah said that to a user, their question is first level important. We can assume that they want it up at the main heading level in a toc, or it is useless to them. So again, think indexes, we are the great levelers for people who think their search is important enough to be available on a first level basis.
I wish she had tested indexes, but oh well.
Links inside a paragraph lose users completely.
Vocabulary was a huge issue - again, there we can help teach users the domain language.
Information architecture in claymation
02/23/10 16:31

This is the
winner of the Explain IA award.
Go watch! Be careful of the bleeped language,
though. Yes, bleeps seem to be required in the
explanation
This will probably be required reading
01/28/10 10:30
I downloaded it as an iPod app for 4.99. The index doesn't work on the ipod, but I bet it does on the Kindle edition. There are no page numbers, and the subheads are blue link-looking text, so I would bet that Peter Morville understands that indexes must be alive. I hate reading on a teeny screen, but for 4.99, heck, that's a deal.
Search and the end of hand-crafted content
12/15/09 10:07
Seems that
Paul Kedrosky has realized
that searching on Google for commonly used (and
bought) terms leads you to endless amounts of
generated useless content. Hmmm.
Over the weekend I tried to buy a new dishwasher. Being the fine net-friendly fellow that I am, I began Google-ing for information. And Google-ing. and Google-ing. As I tweeted frustratedly at the tend of the failed exercise, "To a first approximation, the entire web is spam when it comes to appliance reviews".
This is, of course, merely a personal example of the drive-by damage done by keyword-driven content -- material created to be consumed like info-krill by Google's algorithms. Find some popular keywords that lead to traffic and transactions, wrap some anodyne and regularly-changing content around the keywords so Google doesn't kick you out of search results, and watch the dollars roll in as Google steers you life-support systems connected to wallets, i.e, idiot humans.
Google has become a snake that too readily consumes its own keyword tail. Identify some words that show up in profitable searches -- from appliances, to mesothelioma suits, to kayak lessons -- churn out content cheaply and regularly, and you're done. On the web, no-one knows you're a content-grinder.
The result, however, is awful. Pages and pages of Google results that are just, for practical purposes, advertisements in the loose guise of articles, original or re-purposed. It hearkens back to the dark days of 1999, before Google arrived, when search had become largely useless, with results completely overwhelmed by spam and info-clutter.
Google has to know this. The problem is too big and too obvious to miss. But it's hard to know what you can do algorithmically to solve the problem.
Do read the rest, about content farms.
Over the weekend I tried to buy a new dishwasher. Being the fine net-friendly fellow that I am, I began Google-ing for information. And Google-ing. and Google-ing. As I tweeted frustratedly at the tend of the failed exercise, "To a first approximation, the entire web is spam when it comes to appliance reviews".
This is, of course, merely a personal example of the drive-by damage done by keyword-driven content -- material created to be consumed like info-krill by Google's algorithms. Find some popular keywords that lead to traffic and transactions, wrap some anodyne and regularly-changing content around the keywords so Google doesn't kick you out of search results, and watch the dollars roll in as Google steers you life-support systems connected to wallets, i.e, idiot humans.
Google has become a snake that too readily consumes its own keyword tail. Identify some words that show up in profitable searches -- from appliances, to mesothelioma suits, to kayak lessons -- churn out content cheaply and regularly, and you're done. On the web, no-one knows you're a content-grinder.
The result, however, is awful. Pages and pages of Google results that are just, for practical purposes, advertisements in the loose guise of articles, original or re-purposed. It hearkens back to the dark days of 1999, before Google arrived, when search had become largely useless, with results completely overwhelmed by spam and info-clutter.
Google has to know this. The problem is too big and too obvious to miss. But it's hard to know what you can do algorithmically to solve the problem.
Do read the rest, about content farms.
Mal Booth at ANZSI conference
10/16/09 13:57
Mal Booth
gave the opening sessions at the ANZSI conference in
Sydney yesterday. Great speaker, and there is no way
his slide set captures his speech, but it is
available at http://www.slideshare.net/malbooth/miscellaneous-connections
Google is going to find landmarks
08/01/09 10:38
From
Scientific American:
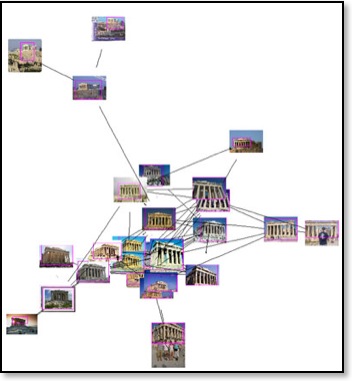
While it's possible to search the Web for images, there's still no way of searching the images themselves. Google is hoping to change this through a research project that can match digital photos of certain famous landmarks with text descriptions of those landmarks (including their namesname and where they're located) without the need for a conventional search engine.
Google created its experimental landmark recognition engine by developing a list of targeted landmarks (such as the Eiffel Tower and the Acropolis in Athens) and finding GPS-tagged digital photos of those locations. The researchers then "taught" the recognition engine to identify specific landmarks by clustering different images of the same landmark (taken in different lighting and from different angles, for example).
While it's possible to search the Web for images, there's still no way of searching the images themselves. Google is hoping to change this through a research project that can match digital photos of certain famous landmarks with text descriptions of those landmarks (including their namesname and where they're located) without the need for a conventional search engine.
Google created its experimental landmark recognition engine by developing a list of targeted landmarks (such as the Eiffel Tower and the Acropolis in Athens) and finding GPS-tagged digital photos of those locations. The researchers then "taught" the recognition engine to identify specific landmarks by clustering different images of the same landmark (taken in different lighting and from different angles, for example).
What is technology going to do?
07/15/09 11:24
From the
Book Oven (Hugh McGuire), and
from a much longer post:
Here are some of the things that are coming, I think, from the inevitable drive of technology to order nature, and our human desire to have efficient sorting systems:
We’ll continue to cataloging everything (from books to people to places) online, and find better ways to sort all that information, using objective authority (eg authoritative incoming links, aka google juice), personal network authority (links/preferences from your chosen network) as relevance indicators.
We will map this network on the web, and increasingly apply it to physical space (starting with google maps, and becoming more customized and personalized)
Mobile technology will mean both that our access to cataloged information becomes ubiquitous, and our efforts to catalog things will be unconstrained
RFID, or something like it, will mean that this sorting of physical objects will move from its current general state (eg. tracking & finding something like “any copy of a certain book”), to specific (eg. tracking & finding something like “a particular copy of a certain book”), and will touch people too
We’ll get all the media we want, when we want it
We’ll get most of the data we want, when we want it
Our mobile devices will increasingly interact with our physical surroundings (point at an object, get info on it; buy it; sell it), and will become our bank, and keys, our thermostat, and more, as well as everything else it already is (telephone, email, library, map etc).
All data on the web will become structured, and mostly available
More data sets (eg government-owned) will arrive on the web, and more people will participate in using that data to understand the world, and make decisions, to order nature
Data about people will become structured, and mostly available [For a well-networked human in my circle, this has already happened: I can track their interests, on a daily basis (del.icio.us, google reader shared items, digg etc.), their movements (dopplr), their public thoughts (blogs, twitter), books they like (librarything, gutenberg bookshelf), things they buy, etc etc.]
Lots of money will be made (if all goes well, some of it by friends of mine) finding new and different ways to do all this, and more and more. In essence, we’ll continue to use the web (and increasingly, mobile devices) to better order nature. And we’ll become better ordered at the same time.
Looking at this very brief list of what’s going to happen, I can’t help but think: “so what?” Is any of this going to make people’s lives richer or more meaningful?
My suspicion is “no.” I say this as a digital native, if a relatively recent, adoptive native (starting in 2004). For myself, I have found that the price of the benefits of the web has been heavy: while the web has allowed me to do all sorts of things, to build things and relationships, and projects, I find the quality of my time on the web so often unsatisfying. In a comparison of value to me between a random “leisure” hour on the web and a random hour doing something else in the real world, the real world trumps the web almost every time. Yet the web still usually wins the battle for my time (this says as much about me as it does about the web, of course).
Here are some of the things that are coming, I think, from the inevitable drive of technology to order nature, and our human desire to have efficient sorting systems:
We’ll continue to cataloging everything (from books to people to places) online, and find better ways to sort all that information, using objective authority (eg authoritative incoming links, aka google juice), personal network authority (links/preferences from your chosen network) as relevance indicators.
We will map this network on the web, and increasingly apply it to physical space (starting with google maps, and becoming more customized and personalized)
Mobile technology will mean both that our access to cataloged information becomes ubiquitous, and our efforts to catalog things will be unconstrained
RFID, or something like it, will mean that this sorting of physical objects will move from its current general state (eg. tracking & finding something like “any copy of a certain book”), to specific (eg. tracking & finding something like “a particular copy of a certain book”), and will touch people too
We’ll get all the media we want, when we want it
We’ll get most of the data we want, when we want it
Our mobile devices will increasingly interact with our physical surroundings (point at an object, get info on it; buy it; sell it), and will become our bank, and keys, our thermostat, and more, as well as everything else it already is (telephone, email, library, map etc).
All data on the web will become structured, and mostly available
More data sets (eg government-owned) will arrive on the web, and more people will participate in using that data to understand the world, and make decisions, to order nature
Data about people will become structured, and mostly available [For a well-networked human in my circle, this has already happened: I can track their interests, on a daily basis (del.icio.us, google reader shared items, digg etc.), their movements (dopplr), their public thoughts (blogs, twitter), books they like (librarything, gutenberg bookshelf), things they buy, etc etc.]
Lots of money will be made (if all goes well, some of it by friends of mine) finding new and different ways to do all this, and more and more. In essence, we’ll continue to use the web (and increasingly, mobile devices) to better order nature. And we’ll become better ordered at the same time.
Looking at this very brief list of what’s going to happen, I can’t help but think: “so what?” Is any of this going to make people’s lives richer or more meaningful?
My suspicion is “no.” I say this as a digital native, if a relatively recent, adoptive native (starting in 2004). For myself, I have found that the price of the benefits of the web has been heavy: while the web has allowed me to do all sorts of things, to build things and relationships, and projects, I find the quality of my time on the web so often unsatisfying. In a comparison of value to me between a random “leisure” hour on the web and a random hour doing something else in the real world, the real world trumps the web almost every time. Yet the web still usually wins the battle for my time (this says as much about me as it does about the web, of course).
Bing vs. Google
06/14/09 10:45
I have been
researching a couple of topics lately, and getting
nowhere finding good information - one is whether or
not you could hook up a USB wireless modem to Airport
Extreme and use that for your wireless network modem.
I googled all kinds of things to try and find
information on that.
I decided today to try Bing and see what happened. First hit. Even with the word "airport" which often means planes, not Apple airport to google.
So then I tried my friend's name, which on google brings up a lot of his articles, but not his website. Bing brought up the website as the first hit.
I'm impressed, which is hard to be, since I am a curmudgeon about things Microsoft. I didn't think there would be much of a difference, but trying it with "known items that have been failing" impressed me.
I decided today to try Bing and see what happened. First hit. Even with the word "airport" which often means planes, not Apple airport to google.
So then I tried my friend's name, which on google brings up a lot of his articles, but not his website. Bing brought up the website as the first hit.
I'm impressed, which is hard to be, since I am a curmudgeon about things Microsoft. I didn't think there would be much of a difference, but trying it with "known items that have been failing" impressed me.
Search Engine Conference presentations available online
05/15/09 10:37
Infonortics has posted PDFs and interviews online
of their recent Boston search engine meetings. Lots
of ideas there, from why today's search engines are
not ready for tomorrow's information needs, to
searching non-text images, voice and video, to
searching with voice interfaces. A lot of technical
information, but worth looking through.
It's really great to make conference material available this way! (Hint hint to all the ASI presenters who haven't posted handouts? See how nice this is to be able to review?)
It's really great to make conference material available this way! (Hint hint to all the ASI presenters who haven't posted handouts? See how nice this is to be able to review?)
Wolfram Alpha - new challenge to Google
05/08/09 10:31
Evidently
in certain arenas of knowledge, yes. Across the
board, no.
Wolfram Alpha is like a cross between a research library, a graphing calculator, and a search engine. But does Wolfram Research's "computational knowledge engine," set to debut publicly later this month, live up to its hype as a Web site that Google needs to be afraid of?
Wolfram Alpha is like a cross between a research library, a graphing calculator, and a search engine. But does Wolfram Research's "computational knowledge engine," set to debut publicly later this month, live up to its hype as a Web site that Google needs to be afraid of?
Carewords vs. search terms
04/05/09 11:02
Gerry McGovern has a nice
piece on how searchers change their terminology as
they search and arrive at sites.
Understanding how people search is extremely important but is only part of the battle to understand what people actually want when they search. Over a typical 12 month period about 25 million people search for a "cheap hotel."
But what does that mean? I have often searched for a "cheap hotel" but I'm not actually looking for a 'cheap' hotel. What I'm really looking for is a 4 or 5 star hotel at a cheap price. And I would certainly not be impressed if I arrived at a hotel website that had a big sign saying: "Welcome to our Cheap Hotel."
About 16 million people search for "hotel deals" every year, but only 18,000 search for "hotel special offers". However, we have found in testing that on a webpage, people respond better to text containing "special offers" than "deals."
He proposes that the search terms used as the search progresses are actually "carewords," terms that people want to see when they arrive, and that these carewords are often not the same as the words used in the search.
Understanding how people search is extremely important but is only part of the battle to understand what people actually want when they search. Over a typical 12 month period about 25 million people search for a "cheap hotel."
But what does that mean? I have often searched for a "cheap hotel" but I'm not actually looking for a 'cheap' hotel. What I'm really looking for is a 4 or 5 star hotel at a cheap price. And I would certainly not be impressed if I arrived at a hotel website that had a big sign saying: "Welcome to our Cheap Hotel."
About 16 million people search for "hotel deals" every year, but only 18,000 search for "hotel special offers". However, we have found in testing that on a webpage, people respond better to text containing "special offers" than "deals."
He proposes that the search terms used as the search progresses are actually "carewords," terms that people want to see when they arrive, and that these carewords are often not the same as the words used in the search.
Searching the deep web
02/24/09 08:09
“The crawlable Web is the tip of the iceberg,” says Anand Rajaraman, co-founder of Kosmix (www.kosmix.com), a Deep Web search start-up whose investors include Jeffrey P. Bezos, chief executive of Amazon.com. Kosmix has developed software that matches searches with the databases most likely to yield relevant information, then returns an overview of the topic drawn from multiple sources.
The New York Times does a survey of new companies and research efforts that will lead to the ability to search deep databases on the Web. Considering that each database structure is unique, and the search interfaces are also unique, this is a horrific problem. Some groups are coming close to solutions.
Seeking information - four common modes
02/05/09 15:30
Donna
Spencer has a very nice article on how users try to
search for information, and the four differing modes
they can be in during a search. Indexing with these
four modes in mind is a great way to increase the
findability in an index.
Boxes and Arrows, Four Modes of Seeking
Information and How to Design for Them
1. Known-item
Known-item information seeking is the easiest to understand. In a known-item task, the user:
*Knows what they want
*Knows what words to use to describe it
*May have a fairly good understanding of where to start
2. Exploratory
In an exploratory task, people have some idea of what they need to know. However, they may or may not know how to articulate it and, if they can, may not yet know the right words to use. They may not know where to start to look. They will usually recognise when they have found the right answer, but may not know whether they have found enough information.
3. Don’t know what you need to know
The key concept behind this mode is that people often don’t know exactly what they need to know. They may think they need one thing but need another; or, they may be looking at a website without a specific goal in mind.
4. Re-finding
This mode is relatively straightforward—people looking for things they have already seen. They may remember exactly where it is, remember what site it was on, or have little idea about where it was. A lot of my personal information seeking is hunting down information I have already seen. I don’t know how prevalent this is, but discussions with others indicate that I am not alonee.
I highly recommend this article - and the Boxes and Arrows site in general for keeping up on searching, findability, and usability, not to mention metadata and taxonomies.
1. Known-item
Known-item information seeking is the easiest to understand. In a known-item task, the user:
*Knows what they want
*Knows what words to use to describe it
*May have a fairly good understanding of where to start
2. Exploratory
In an exploratory task, people have some idea of what they need to know. However, they may or may not know how to articulate it and, if they can, may not yet know the right words to use. They may not know where to start to look. They will usually recognise when they have found the right answer, but may not know whether they have found enough information.
3. Don’t know what you need to know
The key concept behind this mode is that people often don’t know exactly what they need to know. They may think they need one thing but need another; or, they may be looking at a website without a specific goal in mind.
4. Re-finding
This mode is relatively straightforward—people looking for things they have already seen. They may remember exactly where it is, remember what site it was on, or have little idea about where it was. A lot of my personal information seeking is hunting down information I have already seen. I don’t know how prevalent this is, but discussions with others indicate that I am not alonee.
I highly recommend this article - and the Boxes and Arrows site in general for keeping up on searching, findability, and usability, not to mention metadata and taxonomies.