Books people buy
New literacy - new book styles - what about the index?
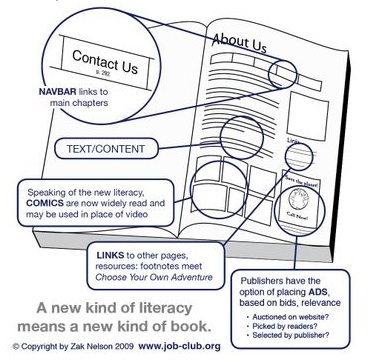
On WebInkNow, David Meerman Scott and Zak Nelson talk about making books more like web pages. I can see some cases where this model might work, but when I read Information Anxiety by R. S. Wurman, the design of that book, much like Nelson's idea shown above, drove me into a state of information anxiety. I must be rather linear. This much material on a page would interrupt the flow of long reading. It could have its place in guidebooks, and short content with many field-like features. Where could the index play a role? As a generator of cross references and related materials, perhaps.
Searching the deep web
“The crawlable Web is the tip of the iceberg,” says Anand Rajaraman, co-founder of Kosmix (www.kosmix.com), a Deep Web search start-up whose investors include Jeffrey P. Bezos, chief executive of Amazon.com. Kosmix has developed software that matches searches with the databases most likely to yield relevant information, then returns an overview of the topic drawn from multiple sources.
The New York Times does a survey of new companies and research efforts that will lead to the ability to search deep databases on the Web. Considering that each database structure is unique, and the search interfaces are also unique, this is a horrific problem. Some groups are coming close to solutions.
Some people do talk about indexes
I wandered through Nothing but Bonfires to find this almost novel-esque discussion.
"Hey Hol, did you know that both 'indexes' and 'indices' are correct?"
"Uh, yes. Actually, I think I did know that."
"Well, don't you think that's kind of unfair?"
"Unfair? What do you mean, unfair?"
"Well, say you use 'indices' in conversation. Then people know that you know a little something, right?"
"Right."
"But if you can say 'indexes' as well, and it's still correct, then that seems like sort of a cop-out. No-one's going to be impressed with 'indices' anymore. They're not going to think that you know a little something. They're just going to think you're the kind of tool who says things like 'indices' when 'indexes' will do just as well."
It's nice to know someone talks about indexes. The ebook lack of consciousness has been making me blue.
Kindle vs. iPhone (and no, I don't have either... )
Unless the Kindle opens up, I don't see it winning this war. Reading books aloud to me is not the major feature I would have jumped for in this release. I would have jumped for good internet access, but I guess there's no money to be made there.
Karen Templer on the Readerville weblog thinks that there will be an iPhone app for Kindle books soon, but that it will come with a price - you will have to have a Kindle to use it. This will not be convergence, or a clear winner.
Reading various accounts around the web of the Amazon press conference this morning, I’ve seen some lamenting that there was no announcement of an iPhone app, with the suggestion that was expected. Certainly the remarks last week begged speculation, but the more I think about it, the less I think they’re on the brink of simply making Kindle-format books available for other devices. That’s what they’ll have to do if they want the whole Kindle concept to survive for the long term, but it seems to me that, for now at least, they’re deeply invested (literally and figuratively) in the device—in making Kindle-format books available to Kindle owners. So while I can see them releasing an iPhone app this year, I don’t see it as standalone access for the purchase and enjoyment of Kindle books. I see it as a way to enable people with Kindles to sync those books onto their phones when going places without the Kindle. (In fact, here’s how PW put it: “… Bezos said Amazon is working on ways to sync the Kindle to other mobile devices.”) In other words, an iPhone app will cost you $359, Kindle included.
And no one mentions the index, anywhere, ever. It's discouraging.
Books in a world of spoken words by Michael Bhaskar

This is an interesting presentation following the changes from oral communication into print, and from print to texting to spoken word in the YouTube age. Somewhere I have read that the young demographic is now using Youtube instead of Google to do searches. A change to spoken searching? Lots of food for thought, and I wish we had the speaker's notes.
Hazel Bell's new book!

From Flock Beds to Professionalism: A History of Index-Makers by Hazel K. Bell
Oak Knoll Press, US, 2008 (ISBN 978-1-58456-228-3) $95.00
HKB Press, UK, 2008 (ISBN 978-0-9552503-4-7) £49.00
340 pp., hardcover
Order it from Oak Knoll Books or from or from HKB Press
or from Amazon UK or from Amazon US
Nancy Mulvany: "It is difficult to express the breadth of this book. .. Hazel Bell has embraced the profession of indexing and made it visible and entertaining. She serves indexers well." — LOGOS
From the publisher's blurb:
"Indexing
is an anonymous profession. An index may be praised
or blamed, but rarely is the indexer named, lauded or
shamed," laments Professor David Crystal in his
preface to From Flock Beds to Professionalism. This
book, however, initiates a change.
Hazel Bell presents here brief biographies of 65
individual practitioners, the makers of indexes, from
the fifteenth to the twentieth century, considering
their working methods, techniques, training,
remuneration, their lives and their personalities.
Crystal observes, "Although it is the history of
indexing which governs the structure of the book, it
is the personalities of the indexers themselves which
shine through it ... I was unprepared for the range,
diversity and sheer brilliance of the personalities
lying behind the names."
After the
biographical section on the "Lone Workers," Bell
outlines in "Banding Together" the history of groups
and societies of indexers world-wide up to 1995, the
year she sees as entailing the end of print-only
indexing. The book includes photographs of indexers
and of their tokens of recognition.
Hazel Bell has been a freelance indexer since 1964, having compiled to date more than 700 indexes to books and journals, and won the Wheatley Medal for an outstanding index in both 2005 and 2006. She has been a member of the Society of Indexers for 44 years, serving on its Council as editor of its journal, The Indexer, for 18 of them. In 1997, she was presented by the Society with the Carey Award for services to indexing. She has written many articles for The Indexer and other learned journals. Bell is the author of Indexers and Indexes in Fact and Fiction (British Library/University of Toronto Press, 2001) and Indexing Biographies and Other Stories of Human Lives (Society of Indexers, 3rd edition 2004). Co-published with HKB Press.
I can't wait to read it, Hazel, it sounds wonderful!
XML in publishing
For Young, the reason to use XML is simple--it allows
Hachette to develop and deliver content to readers in
the formats they want. It also saves money on
production costs and can lead to new revenue streams.
Young noted there are some estimates that put the
number of handheld devices in the world at 3 billion,
which, he said, equates to “3 billion blank pages.”
To reach that audience, content needs to be flexible
enough to be delivered in a variety of ways, Young
said. Since XML uses a content-centric,
design-agnostic approach to production, an XML file
is uniquely suited to deliver content as an e-book or
through print-on-demand, he said.
The effective use of XML, however, requires
cooperation and commitment throughout the production
process, beginning with editors and authors, Young
said. By using XML to tag content, editors are in a
position to help shape how that content will be
delivered, Young said, predicting that “tagging will
become as ingrained as the blue pencil.” Young
acknowledged that editors will need to be trained on
how to tag and that they will need to develop new
skills and have new tools. “It will be a sea change”
about who does what, Young said, but ultimately the
changes will open up new revenue opportunities.
Speakers on the rest of the morning’s panels expanded
on various themes introduced by Young. Brian O’ Leary
of Magellan Media Consulting Partners, said that
publishers will only be able to fully capitalize n
XML if they adopt a discipline approach to using it,
which begins with editors tagging the information. He
noted that some types of books will work benefit more
from XML than others (a point made by one of the
conference organizers, Mike Shatzkin in his What the
Hell is XML piece which appeared in the Dec. 15 PW).
Rebecca Goldthwaite of Cengage Learning noted that
among the lessons learned in implementing XML there
was the need for a “culture change,” and for XML to
be used consistently throughout. Simon &
Schuster’s Steve Kotrch emphasized the ability using
XML gives a publisher to create more robust rights
databases that can be hooked to other databases to
exchange information.
Evan Schnittman of Oxford University Press touched on
the benefits of using XML in terms of improving
search results on Google. The ability to put books
(and other content) into “chunks” enhances the
chances that those books will be discovered through
traditional Google searches rather than only through
Google Book Search, Schnittman said. He noted that
OUP has created a “significant revenue stream” as a
result of its books being discovered through Google.
OUP has 15,564 titles in Google Book Search, which
have generated more than 143 million page views,
Schnittman said which in turn has led to more than
734,000 clicks on a buy link or 47.2 buy clicks per
book. Bill O’Brien of the Copyright Clearance Center
also brought up chunking, noting that chunking leads
to “micro commerce,” which can accumulate late into a
significant sum. (CCC has dispersed $1 billion to
publishers since it was launched 30 years ago, he
said).
Multipurposing material is where they are looking to make their money next.
Wright Information is actively blogging at Indexers Network

I'm actively blogging at Indexers Network, but I will try to post duplicate entries here on indexing topics.
Lists of free ebooks
Are you a grammar snob? A spelling perfectionist?

First, for people who hate unnecessary quotation marks, we have Unnecessaryquotes.com, a blog documenting "too" many "unnecessary" quotes.
And if it is grammar and misspelling, check out the Grammar Vandal, where you will find tales of entire towns banning the apostrophe, and world's worst birthday cake mistakes.
Seeking information - four common modes
1. Known-item
Known-item information seeking is the easiest to understand. In a known-item task, the user:
*Knows what they want
*Knows what words to use to describe it
*May have a fairly good understanding of where to start
2. Exploratory
In an exploratory task, people have some idea of what they need to know. However, they may or may not know how to articulate it and, if they can, may not yet know the right words to use. They may not know where to start to look. They will usually recognise when they have found the right answer, but may not know whether they have found enough information.
3. Don’t know what you need to know
The key concept behind this mode is that people often don’t know exactly what they need to know. They may think they need one thing but need another; or, they may be looking at a website without a specific goal in mind.
4. Re-finding
This mode is relatively straightforward—people looking for things they have already seen. They may remember exactly where it is, remember what site it was on, or have little idea about where it was. A lot of my personal information seeking is hunting down information I have already seen. I don’t know how prevalent this is, but discussions with others indicate that I am not alonee.
I highly recommend this article - and the Boxes and Arrows site in general for keeping up on searching, findability, and usability, not to mention metadata and taxonomies.
A taxonomy of messiness

Linde Brocato turned me on to A Perfect Mess by Eric Abrahamson and David Freedman. Here's the taxonomy of messes:
Types of Mess:
Clutter
Mixture
Time sprawl
Improvisation
Inconsistency
Blur
Noise
Distraction
Bounce
Convolution
Inclusion
Distortion
The authors also propose that mess can be categorized by:
Width
Depth
Intensity
There's something very satisfying about classifying mess, or messing up classifications. A good read - recommended!
Do tags work? By Cathy Marshall

An entertaining study of photo tags on Flickr reveals user tags to be somewhat, um, lacking... In a study of photos of a mosaic of a bull in Milan, one that has a good luck ritual associated with it, Marshall found taggers tagging photos with retrievability-hampered results. In other words, the average joe isn't very good at tagging, even for their own data.
The message
here is almost painful: a great proportion of user
tags add little or no further information; as such,
they don't appear as often in narratives or titles.
Personal names, which may be quite useful for finding
photos among one's own collection (especially over
the long haul) are less well represented in all types
of metadata, but are relatively similar in quantity.
Now here's a property of tags that I find almost
comical: they are seldom verbs, even if a verb is
just the thing to characterize a photo. What's unique
about what tourists do when they visit the Galleria's
bull mosaic? They spin. In fact, if you type in Milan
spin as your Flickr search terms, you pull up 94
results, 70 of which are pictures of our bull mosaic.
20 out of 24 results on the first page are on target.
Although spin and spinning make the top 20 list of
tags, they are by no means commonly used terms; they
are used less than 1% of the time (0.7%). That's just
7 tags. On the other hand, spin makes up 4.8% and
9.5% of title and narrative terms. People just don't
seem to be thinking of tags as verbs.